この記事は CAMPHOR- Advent Calendar 2018 20日目の記事です.昨日の記事は @lotz 氏の「“アルゴリズムこうしん”のアルゴリズムをHaskellで実装する」でした.
wsgi_lineprof は WSGI ミドルウェアとして実装された Python のラインプロファイラです.この記事では wsgi_lineprof がどのようにして実装されているかを,WSGI や CPython の内部実装の簡単な説明とともに紹介します.プロファイラの実装について興味がある人や,Python 処理系,WSGI の裏側に興味がある人の参考になれば幸いです.
wsgi_lineprof とは
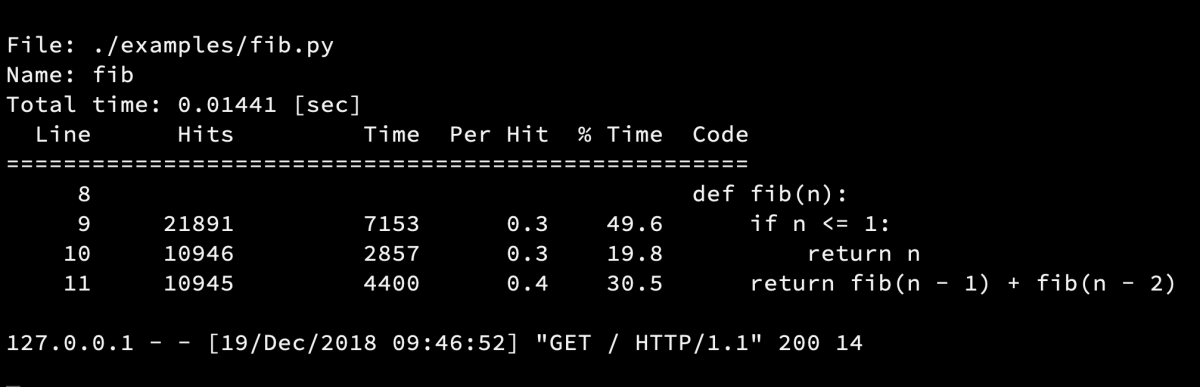
まず簡単に wsgi_lineprof を紹介します.wsgi_lineprof は上でも述べたように WSGI ミドルウェアとして実装された Python のラインプロファイラです.ラインプロファイラというのは,プログラムのソースコードの行単位で実行にかかった時間を計測できるプロファイラです.実際に wsgi_lineprof が出力したプロファイル結果を以下に示します.
File: ./examples/fib.py
Name: fib
Total time: 0.01441 [sec]
Line Hits Time Per Hit % Time Code
====================================================
8 def fib(n):
9 21891 7153 0.3 49.6 if n <= 1:
10 10946 2857 0.3 19.8 return n
11 10945 4400 0.4 30.5 return fib(n - 1) + fib(n - 2)
この結果から,プログラムの9行目は 21,891 回実行され,7,153μs かかったことが分かります.この関数の実行にかかった時間のうち,49.6% の時間が9行目の実行に利用されています.このように wsgi_lineprof を使うとソースコードの行単位でどの部分で時間がかかったかを簡単に知ることができます.
この記事では wsgi_lineprof の実装について主に紹介するため,wsgi_lineprof 自体の使い方については詳しく紹介しません.興味のある方は,過去の記事や GitHub を参照して下さい.
wsgi_lineprof のアーキテクチャ
wsgi_lineprof は大きく分けて3つの部分から出来ています.それぞれの部品とその役割は以下の通りです.
- WSGI ミドルウェア: Web アプリケーション・フレームワークとプロファイラを組み合わせる.
- ラインプロファイラ: 行毎の実行時間を出来る限りプログラムの実行速度に影響を与えずに取得する.
- 結果の表示: プロファイル結果を集計して結果を表示する.
この記事ではそれぞれのコンポーネントについて,何をしているのか,どのように実装されているのかを紹介していきます.
WSGI ミドルウェア
wsgi_lineprof は HTTP リクエストが始まったタイミングでプロファイリングを開始し,レスポンスの処理が完了したタイミングでプロファイリングを終了する必要があります.WSGI ミドルウェアとしてプロファイラを実装することで,特定のフレームワークに縛られず,様々なアプリケーションでプロファイラを利用できるようにしています.
WSGI とは
WSGI (Web Server Gateway Interface) は Python における Web サーバーと Web アプリケーションを接続するためのインターフェースです.PEP 333/PEP 3333 で定められており,多くの Web サーバーや Web アプリケーションフレームワーク (WAF) で採用されています. いくつか具体例を挙げてみます:
- Web サーバー: Gunicorn・mod_wsgi (Apache のモジュール)・uWSGI…
- WAF: Bootle・Django・Flask・Pyramid・Zope…
他の言語で類似する技術としては Java の Servlet や Perl の PSGI,Ruby の Rack などがあります.
ここで,WSGI の仕様を簡単に理解するために,単純な WSGI アプリケーションの例を紹介します.
def application(environ, start_response):
start_response('200 OK', [('Content-type', 'text/plain')])
return [b'hello, world']WSGI アプリケーションの仕様はとても単純で,基本的にはリクエストの情報等が含まれた2つの引数を取り, bytes の iterable を返す callable (関数など) です.このアプリケーションは Python 標準に含まれている WSGI 用のサーバーで動かすことができます.次のプログラムを実行して,ブラウザ等で http://127.0.0.1:8000/ にアクセスすると “hello, world” が返ってくることが確認できると思います.
from wsgiref.simple_server import make_server
server = make_server('127.0.0.1', 8000, application)
server.serve_forever()WSGI ミドルウェアとは
WSGI ミドルウェアはサーバーとアプリケーションの間に入れることが出来るコンポーネントで,リクエストやレスポンスに対して様々な処理を行うために利用できます.使用例としてはユーザー認証・ロギング・プロファイリングなどが上げられます.
ミドルウェアは WSGI アプリケーションを引数にとって,WSGI アプリケーションを返す callable として定義することが出来ます.(関数型言語に造詣が深い方にはミドルウェアは高階関数というとわかりやすいかもしれません.また Python のデコレータの定義にも似ています.) 以下の例はリクエストの処理前後に “Before” と “After” というメッセージを表示する単純なミドルウェアです.
def middleware(app):
def wrapped_application(environ, start_response):
print("Before")
response = app(environ, start_response)
print("After")
return response
return wrapped_application
# アプリケーションにミドルウェアを適用する
application = middleware(application)
WSGI や WSGI ミドルウェアについては「WSGIとPythonでスマートなWebアプリケーション開発を」という特集がよくまとまっていると思います.
wsgi_lineprof の WSGI ミドルウェア
wsgi_lineprof の WSGI ミドルウェアはリクエストの処理開始時にプロファイリングを開始し,終了時にプロファイリングを停止するように定義されています.
class LineProfilerMiddleware(object):
# 省略
def __call__(self, env, start_response):
# type: (WSGIEnvironment, StartResponse) -> Iterable[bytes]
# 省略
self.profiler.enable() # プロファイリングを開始
result = self.app(env, start_response)
self.profiler.disable() # プロファイリングを終了
# 省略また,現時点では実装できていませんが,ミドルウェアを拡張することで特定の URL (例: /_wsgi_lineprof) にアクセスされたときに,プロファイリング結果を HTTP 経由で返すといったことも出来そうです.
ラインプロファイラ
次に wsgi_lineprof の中心にあたる,プログラムの行毎の実行時間を測定するラインプロファイラの部分の実装について紹介します.wsgi_lineprof のラインプロファイラは rkern/line_profiler を元に実装しています.
注意: この節で紹介する方法は Python の実装の一つであり標準実装である CPython を前提としています.他の Python 処理系ではこの節で説明された内容が利用できない可能性があります.
プロファイリング方法の比較
プロファイラがプログラムの実行時間を取得する方法について考えます.
Python は標準のプロファイラとして profile/cProfile を提供しています.これは関数単位での実行時間や実行回数のデータを提供してくれますが,行単位の実行時間を得るのには不十分です.
標準ライブラリの trace モジュールはプログラムのどの行が実行されたかのカバレッジ等を取得することが出来るモジュールです.行単位でデータをとることは出来ますが,実際にある行の実行にどれくらいの時間がかかったかは記録できません.
trace モジュール中でも利用されている,sys モジュールの settrace は Python の処理系のトレースに使うための関数 (トレース関数) を設定することが出来ます.トレース関数は “call”・”line”・”return” などのイベントが発生するたびに呼ばれます.このトレース関数としてプログラムを一行実行するのにかかった時間を記録する処理を実装すれば,プログラムの実行にかかった時間が取得できそうです.以下のプログラムを使って sys.settrace の動作を見てみます.
import sys
def fact(n):
assert n >= 0
r = 1
for i in range(2, n + 1):
r *= i
return r
def trace(frame, event, arg):
print(frame, event, arg)
return trace
sys.settrace(trace)
print(fact(3))このプログラムを実行すると以下のような結果が得られます.プログラムが一行実行されるたびに “line” イベントが発生してトレース関数が呼び出されていることが分かります.
<frame at 0x7fe74b600818, file 'settrace.py', line 4, code fact> call None
<frame at 0x7fe74b600818, file 'settrace.py', line 5, code fact> line None
<frame at 0x7fe74b600818, file 'settrace.py', line 6, code fact> line None
<frame at 0x7fe74b600818, file 'settrace.py', line 7, code fact> line None
<frame at 0x7fe74b600818, file 'settrace.py', line 8, code fact> line None
<frame at 0x7fe74b600818, file 'settrace.py', line 7, code fact> line None
<frame at 0x7fe74b600818, file 'settrace.py', line 8, code fact> line None
<frame at 0x7fe74b600818, file 'settrace.py', line 7, code fact> line None
<frame at 0x7fe74b600818, file 'settrace.py', line 9, code fact> line None
<frame at 0x7fe74b600818, file 'settrace.py', line 9, code fact> return 6
6wsgi_lineprof のラインプロファイラ
wsgi_lineprof ではより高速にプロファイリングを行うために,トレース関数を Cython で実装した C 拡張モジュールとし,PyEval_SetTrace という C API を利用してトレース関数を設定しています.sys.settrace は PyEval_SetTrace のラッパーとなっているため,同等の機能をより低いオーバーヘッドで実行することが期待できます.
wsgi_lineprof のトレース関数では,”line” イベントが発生するたびにその行番号と時間を記録します.このイベントはプログラムのその行が実行される前に発生します.そして次の line イベントが発生したタイミングで,前のイベント発生時の時間との差を求めて,ある行の実行にかかった時間を記録しています.
実装の詳細は extensions/extensions.pyx を参照して下さい.
Python の内部実装
ここで PyEval_SetTrace の仕組みに興味がある方のために,Python の内部実装について簡単に紹介します.
Python のソースコードは以下のようなステップを経て実行されます.
- ソースコードをパースツリーに変換する
- パースツリーを抽象構文木 (AST) に変換する
- AST を制御フローグラフ (CFG) に変換する
- CFG を元にバイトコードを出力する
- バイトコードを実行する
PyEval_SetTrace でトレース関数を登録すると,PyThreadState 構造体の c_tracefunc というメンバーに関数が登録されます.(対応するコード) この c_tracefunc はバイトコード実行時にバイトコードの1命令を実行するたびに呼び出され (対応するコード),行の変わり目で “line” イベントが発生するようになっています.(対応するコード)
また,PyEval_SetTrace はバイトコードの実行中に呼び出される関数ですが,行番号をきちんと保持できています.これはソースコードからバイトコードへの変換に至るまで,きちんと行番号と AST やバイトコードとの間での対応が残されているからです.実際にこの対応が保持されていることを変換の途中結果を見ることで確認してみます.
まず,ast モジュールを使うとソースコードをパースした結果の抽象構文木を見ることが出来ます.上の例で分かるように lineno や col_offset といった attribute に,AST のノードがソースコードのどの行・列に対応しているかが記録されています.
>>> program = """a = 1 + 2
... print(a)
... """
>>> import ast
>>> ast.dump(ast.parse(program), include_attributes=True)
"Module(body=[Assign(targets=[Name(id='a', ctx=Store(), lineno=1, col_offset=0)], value=BinOp(left=Num(n=1, lineno=1, col_offset=4), op=Add(), right=Num(n=2,
lineno=1, col_offset=8), lineno=1, col_offset=4), lineno=1, col_offset=0), Expr(value=Call(func=Name(id='print', ctx=Load(), lineno=2, col_offset=0), args=[Name(id='a', ctx=Load(), lineno=2, col_offset=6)], keywords=[], lineno=2, col_offset=0), lineno=2, col_offset=0)])"次に,dis モジュールを使うと,バイトコードを逆アセンブルした結果を表示することが出来ます.一番左側の列が行番号で,その右側に対応するバイトコードが表示されます.
>>> import dis
>>> dis.dis(program)
1 0 LOAD_CONST 0 (3)
2 STORE_NAME 0 (a)
2 4 LOAD_NAME 1 (print)
6 LOAD_NAME 0 (a)
8 CALL_FUNCTION 1
10 POP_TOP
12 LOAD_CONST 1 (None)
14 RETURN_VALUECPython の内部実装に興味がある方は「Python Developer’s Guide – Design of CPython’s Compiler」を読むことをおすすめします.また,CAMPHOR- Advent Calendar 2018 4日目の記事として @yu-i9 が「Python処理系入門 〜”1 + 1″ で学ぶ処理系解読の基礎〜」という記事を書いています.こちらも CPython について解説されているので,興味のある方はぜひ読んでみて下さい.
結果の出力
wsgi_lineprof はプロファイル結果の出力を柔軟に行えるようになっています.この節では結果の出力に利用している技術や工夫について紹介します.
フィルター
特定のファイルや関数のプロファイル結果だけを見たり,実行時間が長かった関数の結果のみを見たりすることでより,より効率的に結果を確認することが出来ます.wsgi_lineprof ではフィルターによってこれらを実現しています.フィルターは wsgi_lineprof.filters で提供されているほか,filter という名前のメソッドを持つクラスか,プロファイリング結果をとってプロファイリング結果を返す callable を定義することで簡単に作ることが出来ます.
filters = [
# 実行時間が1秒以上の関数のみを結果に残すフィルター
lambda stats: filter(lambda s: s.total_time > 1.0, stats)
]
app = LineProfilerMiddleware(app, filters=filters) linecache
プロファイル結果の出力ではファイルと行番号に対応するソースコードを表示しています.効率的にこの処理を行うために,標準ライブラリの linecache というモジュールを利用しています.あまり使用する機会は多くないかもしれませんが,ソースコードに行単位でランダムアクセスする際に便利なモジュールです.
>>> import linecache
>>> lines = linecache.getlines(linecache.__file__)
>>> lines[0]
'"""Cache lines from Python source files.\n'
>>> lines[1]
'\n'
>>> lines[8]
'import sys\n'stream
wsgi_lineprof はデフォルトでは stdout にプロファイル結果を出力します.stream オプションはファイルオブジェクトを指定することができ,結果をファイルに出力することも出来ます.文字列を引数にとる write というメソッドを実装しているオブジェクトであれば 何でも stream として指定できるようになっており,様々な場所に結果を出力することを可能としています.
sync/async
wsgi_lineprof はデフォルトでは同期的にプロファイル結果を出力しますが,async_stream オプションを有効にすると,別スレッドを使って結果を出力するようにすることができます.この機能は @denzow 氏によって提案されたものを元にしています.
あるシンプル Web アプリでのベンチマーク結果を以下に示します.同期的にプロファイル結果を出力すると,プロファイラを使わないときに比べて数msのオーバーヘッドが発生していますが,非同期的に書き込むとオーバーヘッドが数百μs程度で抑えられていることが分かります.
| 設定 | 実行時間 |
|---|---|
| プロファイラなし | 78μs |
| wsgi_lineprof (async) | 266μs |
| wsgi_lineprof (sync) | 7950μs |
まとめ
少しまとまりのない形になってしまいましたが,wsgi_lineprof の仕組みについて,WSGI ミドルウェア・ラインプロファイラ・結果の出力という3つのパートに分けて見ていきました.それぞれの部品に特に新しい技術が利用されているというわけではありませんが,これらをうまく組み合わせることで一つのプロファイラを開発しています.この記事がプロファイラの実装やその関連技術に興味がある人が実装を理解するための一助になれば幸いです.
さて,CAMPHOR- Advent Calendar 2018 明日の担当は @marty1martie です.お楽しみに!